
Last week, Dataminr joined 3,000 of the world’s leading AI researchers at the Association for the Advancement of Artificial Intelligence conference. This was an amazing opportunity for members of our AI team to engage in dialogue about a broad range of the AI techniques we use in our AI Platform—spanning Neural Networks, Deep Learning, and Machine Learning, in the fields of Natural Language Processing, Natural language Generation, Computer Vision, and Multi-Modal Event Detection, among others.
At the conference, I had interesting conversations with top members of the AI research community on varied topics. I also had the opportunity to chat with chess champion Garry Kasparov and Nobel laureate Daniel Kahneman. I asked Kasparov about his thoughts on solving games as being mainly a search problem (every move as a search for the best solution), and whether intelligence could be measured, mainly by how well one transfers that knowledge to another domain. Kahneman and I spoke about whether his “System 1” was like pre-attentive processing, and the role of context.
I also had the chance to hear from many members of the AI research community about a range of techniques that have been developed to detect events using AI.
Across the field of AI today, most techniques for detecting events have focused on single-modality approaches that separately deal with image-only, video-only, sound-only, or text-only inputs. While these single-modality methods can be effective in some circumstances, each runs into limitations.
At Dataminr, we have built the leading real-time AI Platform for detecting global events by processing billions of public data inputs per day in a wide range of formats and from hundreds of thousands distinct data sources. These public data inputs include text, images, video, sound, and public IoT sensor data. Our AI models span natural language understanding, computer vision, sound/audio detection and anomaly detection in machine-generated data streams.
Over years of research and experimentation, we have learned that in many cases, an event can only be detected accurately, as early as possible, by using Deep Learning that combines mutli-modal signals—in other words, a signal that combines more than one type of public data input with more than one field of AI. For this reason, we have focused on early detection multi-modal AI Fusion methods that synthesize diverse and disparate public data sources to discover events.
Today, information about events is shared instantly as public data – often fragmented and in various data formats ranging from text, to images, videos, sound and machine-generated data streams. For example, eyewitness images posted on social media are accompanied by textual first-hand accounts that can provide additional context. During our many years exploring the real-time public information landscape, we have found that in breaking events, information is publicly available in pieces, coming from a wide range of different public sources. Often, it’s only together that these fragments of information provide the full set of puzzle pieces needed to quickly create a complete picture of what has actually happened or what is currently happening.
In order to illustrate how multi-modal detection works, I am going to describe an example of one of these methods with some technical depth—the fusion of image detection (Computer Vision) and textual detection (using Natural Language Understanding) by leveraging Deep Learning Neural Networks.
I’ll start with a high-level explanation of what is meant by the concept of “attention” in Deep Learning, where multiple layers of Neural Networks are used. Then I’ll briefly explain word embeddings, and give a brief overview of how our real-time AI Platform fuses and cross-correlates two modalities: image content using Computer Vision and text using natural language understanding. Both techniques rely on state-of-the-art approaches that leverage multiple layers of Neural Networks whose outputs fuse the most important parts of the image or text signals to more accurately detect events.
Our text and Image AI fusion method consists of several distinct components. Given an image-text pair, our AI Platform generates a feature map for the image, word embeddings for the text, and then leverages a Deep Learning crossmodal attention mechanism to fuse information from the two modalities.
In Deep Learning, “attention” means that an AI algorithm is selective in what data it considers of higher importance, in relation to other data that it deems less important. For example, in a textual sentence published on social media that describes an event, the AI algorithms take into account the first word in a given sentence to better understand and interpret the meaning of subsequent words in the sentence. Some of these words are more strongly related to each other than others and thus have higher “attention”—additionally, not all words contribute equally to the meaning of a sentence.
In images, attention mechanisms function similarly to those in text. How a Computer Vision algorithm interprets a particular section or patch of a given image depends on what the algorithm can “see” surrounding it. Computer Vision algorithms can focus on only certain parts of an image that they deem to be more important to ascertain an event. For example, focusing on a part of an image that depicts the flames of a fire could serve as the critical clue for determining the nature of an event that an image is depicting. Just as with words in sentences, some patches and pixels in the image are far more valuable in identifying real-time breaking events than others. For example, a patch of smoke is more valuable than a patch of sky in determining that a region in the image is likely to be depicting that a fire might be taking place.
Word embeddings are based on the idea that words that have similar context will have similar meanings. Most computational Deep Learning AI methods represent words using vectors of numbers, so that algorithms can use those vectors for different tasks. For example, tasks like an algorithm learning how similar two pieces of text are, or tasks to automatically classify text and label it: vectors are used as features to represent text, and then these features are used in Machine Learning tasks and AI models. Word embeddings are simply a representation of text in which each word is mapped to a real-valued vector, and where the real-values (as opposed to integer-values) are learned by an algorithm. Following this logic, words with similar values are interpreted as having similar meanings.
Word embeddings have played a major role in recent progress in using Deep Learning for Natural Language Processing (NLP). Additionally, attention mechanisms in Computer Vision have led to significant accuracy improvements in a wide range of detection tasks in images and video. The text and image fusion approach we’ve developed consists of leveraging both techniques jointly, using a novel multi-modal fusion method that synthesizes both image and text as inputs. Our Cross Attention mechanism identifies the most valuable information in the text, in combination with the most valuable information in the image. The model makes use of stochastic shared embeddings to alleviate and prevent overfitting in small data. The basic framework is described in the following figure.
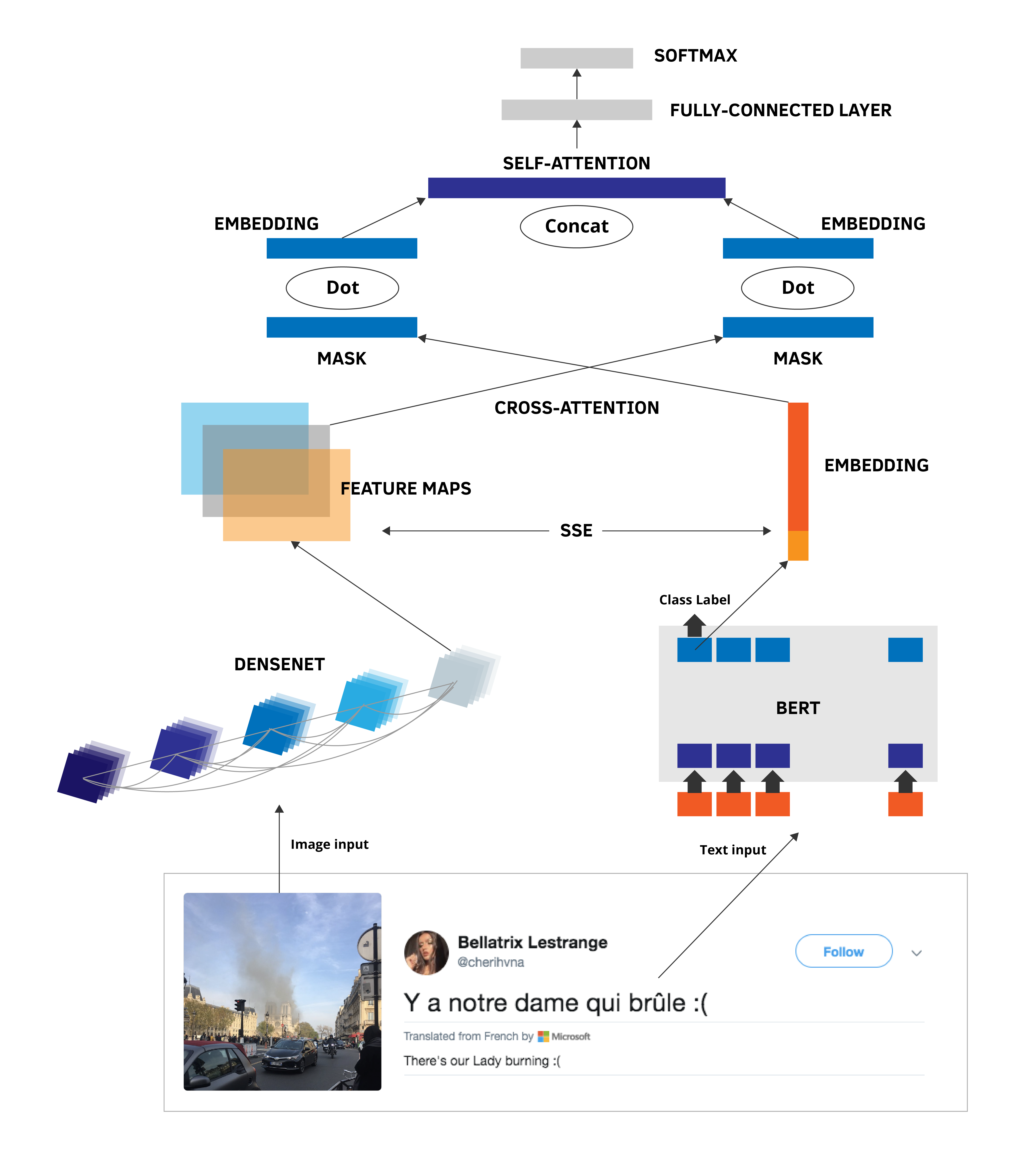
As depicted in this diagram, this methodology consists of 4 parts: the first two parts extract feature maps from the image and extract embeddings from the text, respectively; the third part comprises our crossmodal-attention approach to fuse projected image and text embeddings; and the fourth part uses Stochastic Shared Embeddings (SSE) as our regularization technique to prevent overfitting and deal with training data with inconsistent labels for image and text pairs. The novelty of our approach lies in the cross attention and SSE methods for multi-modal classification, which essentially leverage the most relevant parts of either the image or text components to detect events.
Our multi-modal fusion AI model outperforms single mode or basic multi-modal techniques. For example; it outperforms “state of the art” approaches that only focus on methods that are based on image-only inputs (DenseNet) and text-only inputs (BERT). Additionally, it outperforms multi-modal simple score and feature fusion methods.
The examples outlined above illustrate how Deep Learning based multi-modal AI fusion methods can be used to improve event detection accuracy. AI Multi-Modal fusion has significant potential for the mixture of other data modalities as well. For example, the fusion of video and sound. Often streaming videos of events contain embedded sound fragments that can provide essential clues for event classification of the event depicted in the video. Another example is the fusion of machine-generated data streams and textual and image data. As described in a previous Dataminr blog post, it can be machine generated data from plane transponder signals that provides an initial clue that a plane is in trouble. But, only when a nearby eyewitness social media post is published that includes an image of smoke on the horizon can there be enough digital evidence to suggest a plane crash.
The success of multi-modal event detection has been made possible by combining recent advances in data processing power (in particular GPUs), with Deep Learning Neural Networks, and the exponential increase in publicly available data describing real-time events as they occur across the world. As the volume and diversity of public data describing real-time events continues to expand exponentially, multi-modal event detection methods will only get more effective at detecting events in their earliest moments with greater speed and accuracy.
Deep Learning for Multi-Modal Event Detection will continue to be a core focus of our AI research. At Dataminr, we define ourselves as a real-time AI Platform to encapsulate the volume, velocity and variety of data formats we process in real-time; the wide range of AI techniques and methods we deploy; and the broad collection of AI models we’ve created and integrated. Over the years, we’ve continuously expanded Dataminr’s AI platform to handle extremely large volumes of diverse data in many formats, in real-time, to easily allow us to integrate and deploy a variety of AI techniques, methods, and models. In that process, we’ve built a world class AI Environment that scales exponentially in the creation of different types of alerts, while at the same time maintaining consistency, efficiency and optimized performance. Multi-modal event detection methods allow us to combine the diverse palette of AI building blocks in our AI platform in more sophisticated ways, realizing one of the greatest benefits of the approach we’ve taken in building our real-time AI platform.
Responding to events quickly saves lives and the mission of our AI team is to be continuously innovating — advancing the state of the art in Deep Learning and Neural Networks to continue to push forward the scope of what’s possible with AI. To further expand this experimentation and research, we are currently hiring Ph.D.s in Deep Learning, Machine Learning, Neural Networks, Natural Language Processing, Natural Language Generation, Computer Vision, Information Retrieval, Knowledge Graphs, Complex Networks and Multi-modal event detection. Check here to see if there is a role that is right for you!

Trailblazing GenAI Innovation
Dataminr’s Founder and CEO gives a lightning talk on ReGenAI and the evolution of Dataminr’s AI Platform at the MIT and Forbes' Imagination in Action AI Conference.
WATCH NOW

